说明:
本文首发于 CSDN,转载请保留链接。
前言
今天闲来无事查看下语音识别在ROS中的应用,之前在ROS中玩过一段时间的Pocket Sphinx,关于Pocket Sphinx的学习过程以后会介绍,或者可以去网上搜索一些教程,都是比较不错的。现在讲述下在ROS中百度语音的使用情况,由于百度语音的作者写了一些文章在Github上,但是步骤不是很清楚,在此记录一下防止以后忘记,也和大家分享下,避免出现一些失误而导致半途而废。
需求:
| 软件 | 版本 |
|---|---|
| 操作系统 | Ubuntu 14.04.2 |
| ROS版本 | Indigo |
ROS语音识别介绍
关于一些在ROS中如何使用语音识别库,大家可以自行搜索下,基本上都是在ROS官网上的一些资料,目前官网上的语音识别库一共有四个,分别为
目前讲述的是百度的语音识别,目前百度语音已经支持ROS,大家可以学习下。以后会介绍其他三个语音库。
百度语音识别在ROS中的应用
关于如何在ROS中使用百度语音识别呢,作者也已经在wiki上介绍了,大家可以先查看下,网址是:http://wiki.ros.org/baidu_speech
不过作者貌似没有提供在线安装,也就是apt-get来安装百度语音包,不过不妨碍今天的教程,安装百度语音包的过程如下:
- 在Github上下载百度语音包
- 安装百度语音包的需求包
- 运行并测试百度语音包中的说话者(simple_speaker.launch)和语音识别(simple_voice.launch)
下面根据步骤来进行操作
在Github上下载百度语音识别包
在下载之前,你应该有一个catkin工作空间,我的工作空间名字就是catkin_ws。然后在catkin_ws/src下下载百度语音识别包(simple_voice)
$ git clone https://github.com/DinnerHowe/simple_voice.git
下载完成后其实就可以使用,但是会提示错误,例如:No module named pyaudio 或者 Nomodule named vlc
其实作者也已经说过了,要想使用simple_voice这个包,需要Python库,也就是pyaudio和vlc-python。下面安装需求包。
安装百度语音识别包的需求包
安装pyaudio其实是比较简单的,直接使用下面的命令就可以安装:
$ sudo apt-get install python-pyaudio
这个步骤直接就在线安装了需求包pyaudio。
安装vlc其实比较坑,或许是我的电脑的问题,没有找到在线安装命令也就是python-vlc这个包,就算安装了vlc所有的包也还是提示No module named vlc。
不过最终还是解决了,使用如下方式,首先在你的home下,下载vlc的封装库:
$ cd
$ git clone https://github.com/geoffsalmon/vlc-python.git
下载完成后,使用如下命令加载vlc模型到Python中
$ sudo cp vlc-python/generated/vlc.py /usr/lib/python2.7/
Indigo的Python是2.7版本,大家也可以替换成你当前版本,路径还是/usr/lib。 添加完成需求包后,就可以测试运行百度语音识别包了。
运行并测试百度语音包中的说话者(simple_speaker.launch)和语音识别(simple_voice.launch)
测试simple_speaker.launch
首先打开一个终端,输入如下命令来启动simple_speaker.launch
$ roslaunch simple_voice simple_speaker.launch
作者在网上说直接运行这个launch就可以听到说话,其实还少一步,需要添加音频文件才可以。作者在语音包中给出了一个“请让一下.mp3”,其他音频文件没有测试,大家可以测试下都支持什么音频文件,在此就不讲述了。
运行完simple_speaker.launch后,多出了一个/speak_string的话题,该话题就是接收音频文件,需要手动的添加音频文件到simple_speaker节点,其中该launch文件只开启了一个节点就是simple_speaker。
打开另一个终端,向simple_speaker节点添加音频文件:
$ roscd simple_voice/src
$ rostopic pub /speak_string std_msgs/String -- '请让一下.mp3'
测试simple_voice.launch
关于测试simple_voice.launch是容易的,直接一条命令搞定:
$ roslaunch simple_voice simple_voice.launch
然后对着电脑说话就可以了,比如:
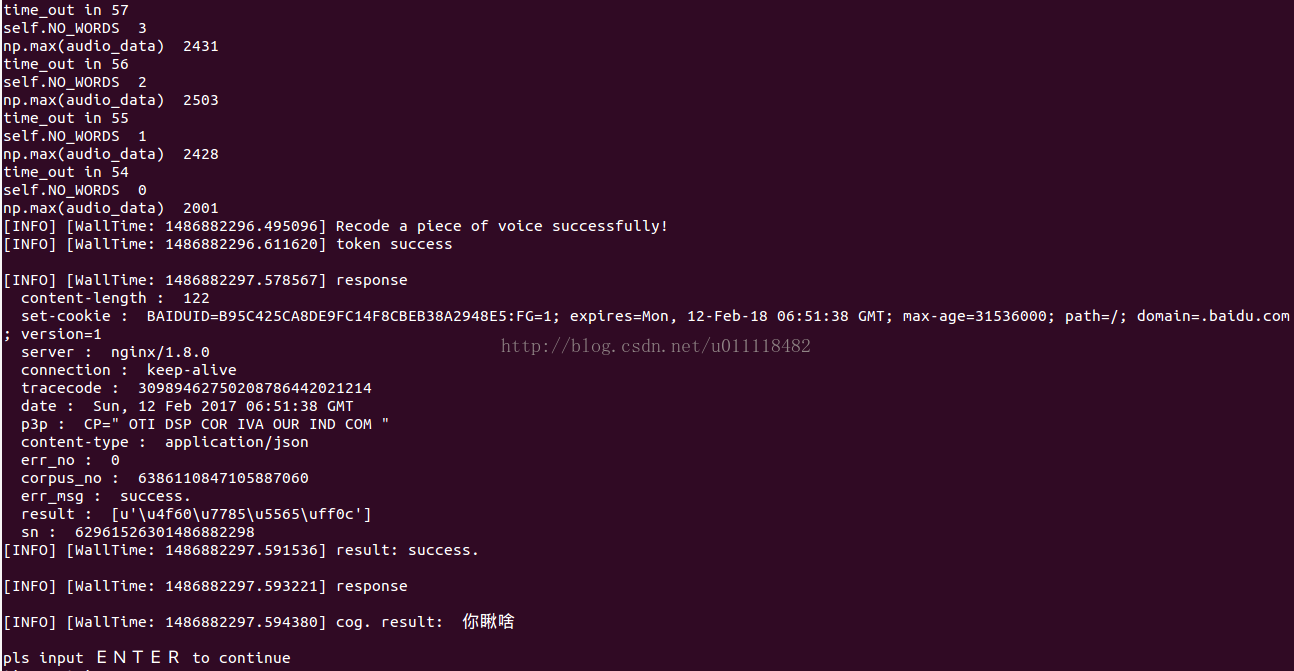
每次只识别一次,识别完成后需要桥下Enter键才能继续识别,当然大家也可以对voice_node.py进行改造,变成实时语音识别。